I am a huge fan of Formula 1 (F1) and have been watching it ever since the close fight between Mercedes and Ferrari drivers in 2018. Over the years, I have developed a keen interest in the developments, communication, and strategies used by teams to optimize their performance and get the best out of their cars. I was amazed by the Mercedes team's development of the DAS (Dual Axis Steering) system in 2020, which allowed drivers to change the toe angle of the front wheels while driving, thus optimizing tire temperature and wear. This led me to explore more about the developments in F1. During my master's degree, I started working on a class and personal project to optimize the strategy of a Formula 1 Grand Prix. I immediately began thinking that there are many factors that can affect the result of a Grand Prix, such as tire wear, fuel consumption, weather conditions, and track characteristics. I wanted to create a model that could simulate the strategy of a Grand Prix and optimize it using reinforcement learning.
Introduction
Formula 1 (F1) racing is an exciting sport that hinges on split-second decision-making and smart strategy (like pit stops during a VSC or SC). For race engineers, the challenge is huge: they must process tons of data to decide when their drivers should pit, which tires to use, and how to react to the constantly changing situation during a Grand Prix. A single mistake can cost precious seconds, or even the entire race. This complexity makes F1 strategy perfect for advanced AI solutions. This blog explains how Deep Reinforcement Learning (DRL), specifically Deep Q-Networks (DQN), can be used to improve these important real-time race strategies. The ideas come from a project that used Markov Decision Process (MDP) modeling and a specially designed reward system.
Formula 1 Race Strategy: The Real World vs. The Goal
What Happens in the Real World?
A typical Grand Prix consists of multiple laps (minimum number of laps needed to exceed 305 kilometers), with drivers competing to finish in the best possible position. Their position on Grand Prix day is decided by their performance during the Qualifying session, which determines the starting grid. The strategy for a Grand Prix involves deciding when to pit, which tires to use, and how to react to changing conditions. The goal is to maximize the driver's position (or Grand Prix points) at the end. Key factors affecting strategy include:
- Tire Selection & Management: Drivers have a limited allocation of tire compounds (typically 8 Soft, 3 Medium, and 2 Hard sets for a race weekend, chosen from a broader range like C0-C5). Each tire type offers a different balance of grip and durability. Managing tire wear and degradation is critical to maintaining race pace.
- Pit Stop Timing: Deciding the optimal lap to pit is a complex calculation involving tire wear, track position, the actions of competitors (an "undercut" or "overcut" strategy), and potential opportunities like safety car periods. A well-timed pit stop can gain significant time over competitors, while a poorly timed one can lead to lost positions.
- Race Pace & Data Analysis: Engineers monitor vast streams of data, including:
- Lap timings (driver's own, competitors', sector times)
- Telemetry data (speed, RPM, gear, tire temperatures, car position)
- Pit stop performance (every second in the pit lane counts)
- Car setup and downforce levels
- Weather conditions (rain can completely overturn strategies)
- Track status (Safety Cars, Virtual Safety Cars, or yellow/red flags heavily influence decisions)
What my Project Aims to Achieve
The core goal of my project was to develop a real-time race strategy optimization system using Deep Reinforcement Learning. The aim was to create an intelligent "agent" capable of learning from data and adaptively adjusting race strategies based on real-time track conditions and car performance. In essence, the project explores whether a DRL model can make strategic decisions that rival, or even surpass, those made by human race engineers under intense pressure.
Deep Reinforcement Learning: The Brains of the Operation
What Is It?
Deep Reinforcement Learning (DRL) is a sub part of machine learning where an agent learns to make optimal decisions by interacting with an environment. The agent performs actions within this environment, observes the resulting state, and receives rewards (or penalties) based on the outcome of those actions. The ultimate objective for the agent is to learn a policy — a strategy for choosing (or next) actions - that maximizes its total accumulated reward over time. The "deep" in DRL refers to the use of deep neural networks (specifically, Q-Learning), which can approximate the value of states or state-action pairs, enabling the agent to handle complex, high-dimensional problems.
How Can It Be Integrated with F1 Strategy?
In the context of F1 strategy optimization, the DRL agent interacts with a simulated environment that mimics the dynamics of a Grand Prix. I model the environment using gymanism module and define the key components:
- Agent: The DRL model itself, tasked with making pit stop and tire selection decisions.
- Environment: The Formula 1 Grand Prix, modeled as a Markov Decision Process (MDP). This means that the future state depends only on the current state and action, not on the sequence of events that preceded it.
- States: A snapshot of the current race situation, represented by various data points. For this project, state features included:
- Driver ID, Current Lap Number, Current Position, Starting Position
- Current and Next Lap Times (in milliseconds)
- Pit Stop Count and Time, Whether a Pit Stop is currently happening
- Track Status (e.g., Clear, Safety Car)
- Currently Fitted Tire Type (Soft, Medium, Hard, etc.) and Tire Age
- Gaps to cars in front and behind, and their lap times
- DRS (Drag Reduction System) availability
- Actions: The decisions the agent can make. These primarily involve:
- Pitting on a specific lap to change to a new set of tires (Soft, Medium, Hard, Intermediate, or Wet). In my project, I have not considered weather conditions or any data points where it rained during the Grand Prix, so the agent only considers the three dry tire compounds.
- Choosing not to pit on a given lap. The total action space depends on the race length (e.g., for a 52-lap race like the British Grand Prix, with 5 tire choices + 1 no-pit option per lap, it's 52 * 6 = 312 possible high-level actions).
- Data Source: The project utilized the FastF1 library, a Python tool that provides access to rich F1 data, including timing, telemetry, and session information. This data was preprocessed, converting string values to numerical representations and time formats to milliseconds.
Deep Q-Learning Approach: The Technical Details
What Exactly Was Done?
The project implemented a Deep Q-Network (DQN), a prominent DRL algorithm, to learn the optimal pit stop strategy. The DQN is a type of neural network that approximates the Q-value function Q-function (Q(s,a)), which estimates the expected future cumulative reward of taking a specific action (a) in a given state (s).
Key Components of the DQN Agent:
The DQN agent was built with several crucial components:
- Initialization: Setting up parameters such as state and action dimensions, learning rate (alpha), discount factor (gamma, which balances immediate vs. future rewards), exploration parameters (epsilon for an epsilon-greedy strategy, epsilon decay rate, and a minimum epsilon value), replay memory buffer size, and batch size for training.
- Q-Network: The deep neural network that approximates the Q-function.
- Optimizer and Loss Function: The Adam optimizer was used to update the network's weights, with Mean Squared Error (MSE) as the loss function to measure the difference between predicted and target Q-values.
- Act Function: This function dictates the agent's behavior. Given the current state, it uses the Q-network to predict Q-values for all possible actions. It then employs an epsilon-greedy strategy:
- Exploit: With probability 1-epsilon, choose the action with the highest Q-value (the best-known action).
- Explore: With probability epsilon, choose a random action. This encourages the agent to discover new strategies. Epsilon typically decays over time, shifting the agent from exploration to exploitation.
- Replay Function (Experience Replay): To improve learning stability and efficiency, the agent stores its experiences (state, action, reward, next state, done flag) in a replay memory buffer. During training, it samples random mini-batches of these experiences to train the Q-network. This breaks the correlation between consecutive experiences.
Q-Learning Architecture:
The DQN architecture consists of an input layer that takes the current state, followed by several hidden layers (fully connected neural network layers) that process the input. The output layer provides Q-values for each possible action. The network is trained to minimize the difference between predicted Q-values and target Q-values, which are calculated using the Bellman equation:
- Input Layer: Size 17, corresponding to the number of features in the state representation (e.g., lap times, tire conditions, gaps to other cars).
- Hidden Layers: Two fully connected (dense) layers, each with 64 hidden units.
- Activation Function: ReLU (Rectified Linear Unit) was used for the hidden layers to introduce non-linearity.
- Output Layer: The size of this layer corresponds to the number of possible actions (e.g., 6 actions per lap: 5 tire choices + 1 "no pit" option, multiplied by the number of laps if the agent decides the lap too). For discrete actions per lap, it's 6. If the network outputs Q-values for all actions over all laps, it would be
race_length * num_tire_options_plus_no_pit. Based on the provided context, it seems the agent likely decides whether to pit on the current lap and which tire if so, meaning an output size related to immediate actions. Let's assume an output size of 6 (5 tire types + 1 no-pit option) for decisions at each lap considered. - Optimizer: Adam, with a learning rate of 0.0001.
- Loss Function: Mean Squared Error (MSE).
- Training: The agent was trained for 500 episodes.
Pseudo Code: Deep Q-Learning Agent Training (General)
1Initialize replay memory D to capacity N
2Initialize action-value function Q with random weights θ
3Initialize target action-value function Q_target with weights θ_target = θ
4
5FOR episode = 1 TO M DO
6 Initialize starting state s_1
7 FOR t = 1 TO T DO // T is max steps per episode
8 With probability ε select a random action a_t
9 Otherwise select a_t = argmax_a Q(s_t, a; θ)
10
11 Execute action a_t in the F1 environment
12 Observe reward r_t and next state s_{t+1}
13 Determine if the episode is done (done_flag)
14
15 Store transition (s_t, a_t, r_t, s_{t+1}, done_flag) in D
16
17 Sample a random minibatch of transitions (s_j, a_j, r_j, s_{j+1}, done_j) from D
18
19 IF done_j THEN
20 y_j = r_j
21 ELSE
22 y_j = r_j + Y * max_{a'} Q_target(s_{j+1}, a'; θ_target)
23 END IF
24
25 Perform a gradient descent step on (y_j - Q(s_j, a_j; θ))^2 with respect to θ
26
27 Every C steps, update target network: θ_target = θ
28 END FOR
29END FOR
30Reward System: The Heart of Learning
The design of the reward system is very important in DRL, as it directly shapes the agent's behavior by defining what constitutes a "good" or "bad" action. The system was carefully crafted to penalize poor tire management and inefficient pit stops while rewarding optimal lap times and smart strategic maneuvers.
Aspects Considered and Why:
- Pit Stop Decisions:
- If the agent decides to pit (on a valid lap, choosing a different tire, and typically if the current tire age exceeds a certain threshold like 15 laps):
- The pit stop count is incremented.
- Tire age is reset for the new tires.
- A penalty is applied. This penalty considers the chosen tire type (e.g., softer tires might incur a smaller intrinsic penalty for choice itself, but this is balanced by wear) and the efficiency of the pit stop (comparing actual pit stop time to an optimal/average time). The
calculate_pit_stop_time_penaltyfunction handles this.
- If the agent decides to pit (on a valid lap, choosing a different tire, and typically if the current tire age exceeds a certain threshold like 15 laps):
- No Pit Stop Decisions:
- Tire age is incremented.
- A reward is calculated based on lap time. The
calculate_lap_time_rewardfunction compares the current lap time to an optimal or average lap time. Faster laps yield higher rewards. Penalties are applied if lap times are significantly slower than optimal, especially with older tires.
- Contextual Factors:
- Track Status: A bonus could be given for pitting under favorable conditions like a Safety Car, as this often minimizes time lost.
- Battles: If drivers are in a close battle, the reward might be slightly adjusted (e.g., reduced by a factor like 0.95) to account for the inherent risks and potential time loss.
- DRS: If a driver has DRS available (an overtaking aid), the reward might be increased (e.g., by a factor like 1.1) to encourage aggressive, pace-pushing laps.
Pseudo Code: Reward System Logic
1FUNCTION calculate_reward(current_state, action, next_state):
2 lap_decision_in_action, tire_choice_in_action = action
3 reward = 0
4
5 IF is_pit_stop_action(action, current_state) THEN
6 // Pit stop occurred
7 increment_pit_stop_count_in_state(next_state)
8 reset_tire_age_in_state(next_state, tire_choice_in_action)
9 penalty = calculate_pit_stop_time_penalty(tire_choice_in_action, current_state.actual_pit_time_if_any)
10 reward = reward - penalty
11 ELSE
12 // No pit stop occurred or action was not a pit stop
13 increment_tire_age_in_state(next_state)
14 lap_time_reward_value = calculate_lap_time_reward(current_state.current_lap_time, current_state.optimal_lap_time, current_state.tire_age)
15 reward = reward + lap_time_reward_value
16 END IF
17
18 // Apply contextual adjustments
19 IF is_pitting_under_safety_car(action, current_state) THEN
20 reward = reward + SAFETY_CAR_PIT_BONUS
21 END IF
22 IF is_in_battle(current_state) THEN
23 reward = reward * BATTLE_PENALTY_FACTOR // e.g., 0.95
24 END IF
25 IF has_drs_available(current_state) THEN
26 reward = reward * DRS_BONUS_FACTOR // e.g., 1.1
27 END IF
28
29 RETURN reward
30END FUNCTION
31
32FUNCTION calculate_pit_stop_time_penalty(tire_choice, actual_pit_milliseconds):
33 // Base penalty associated with choosing a specific tire (can be 0 if not differentiated)
34 // For example, might be higher for riskier strategies or simply a fixed cost for pitting.
35 // The provided text implies penalties are scaled sums of pit time and tire-specific values.
36
37 // Example logic from project description:
38 // tire_penalties = {SOFT: 10, MEDIUM: 20, HARD: 30, INTER: 50, WET: 80}
39 // base_tire_penalty_value = tire_penalties[tire_choice]
40 // if actual_pit_milliseconds < OPTIMAL_PIT_STOP_TIME_MS:
41 // total_penalty = actual_pit_milliseconds + base_tire_penalty_value * 0.5
42 // else:
43 // total_penalty = actual_pit_milliseconds + base_tire_penalty_value
44 // RETURN total_penalty / 1000 // Scaled
45
46 // Simplified:
47 penalty = (actual_pit_milliseconds / 1000.0) // Base penalty for time lost
48 // Add tire choice specific penalty if applicable
49 // penalty += TIRE_CHOICE_PENALTIES[tire_choice]
50 RETURN penalty
51END FUNCTION
52
53FUNCTION calculate_lap_time_reward(current_lap_time_ms, optimal_lap_time_ms, tire_age_laps):
54 time_difference_ms = optimal_lap_time_ms - current_lap_time_ms
55 base_reward = time_difference_ms / 1000.0 // Scaled reward/penalty based on raw time difference
56
57 IF current_lap_time_ms > optimal_lap_time_ms THEN
58 // Apply additional penalty for being slower, potentially scaled by tire age
59 base_reward = base_reward - ((current_lap_time_ms - optimal_lap_time_ms) * TIRE_AGE_PENALTY_SCALAR(tire_age_laps)) / 1000.0
60 END IF
61 RETURN base_reward
62END FUNCTION
63Results: What the Agent Learned
The thoughtfully designed reward system proved effective in guiding the DQN agent to differentiate between actions involving pit stops and those that didn't, learning to make more informed descisions about when to pit and which tires to select. The overall project involved extracting and preprocessing data from FastF1, designing the F1 race environment using MDP modeling, creating the detailed reward system, and then rigorously training and testing the DQN agent, followed by visualizing the outcomes.
The agent's performance was evaluated by comparing its decisions and resulting lap times against a baseline strategy (strategy that was applied during a Grand Prix). I ran the agent through several Grand Prix events, including the British, Brazilian, and Austrian Grand Prix. These predictions were then compared against expected strategies (actual race outcomes). I did not expect it to behave the best F1 strategist but the results demonstrated the agent's capability in several key areas:
- Track Condition Awareness: The agent showed an ability to recognize and potentially exploit periods of track instability, such as making advantageous pit stops during yellow flag or safety car deployments.
- Improved Tire Management:By considering factors like tire age and current performance, the agent made more sensible tire choices, contributing to better lap times and overall race pace.
- Optimal Pit Stop Timing: The agent learned to identify more the best laps to pit, balancing the need for fresh tires against the risks of losing track position. It was able to make pit stop decisions that minimized time loss, especially in scenarios where other drivers were also pitting.
Let me take an example of the British Grand Prix 2020, where the agent was able to predict the pit stop strategy and tire choices effectively. Below is an image of the expected pit stop strategies and windows:
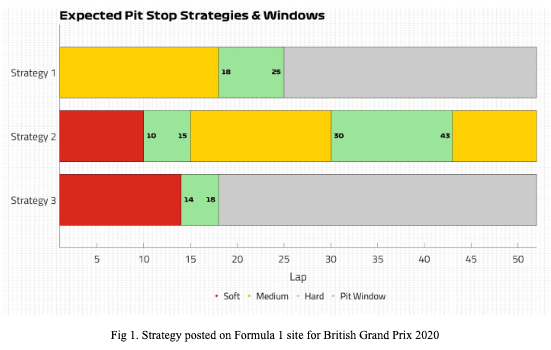
Here is the actual pit stop strategy of the top 5 drivers during the British Grand Prix 2020:

And here is the agent's predicted pit stop strategy for the same Grand Prix, which closely resembles the actual strategies of the top drivers:

The agent was able to predict the pit stop strategy and tire choices effectively, which is a significant achievement given the complexity of the Formaula 1 Pit Stop strategies.

During my experimentation, I understood many aspects of the Formula 1 and it is not just about the Grand Prix day, but also about the Qualifying session, practice sessions, and the overall balance and setup of the car. But I was able to create a simulation that could mimic the decision-making process of a real-world F1 strategist, albeit in a simplified manner. The agent was able to learn from its experiences and adapt its strategy over time, improving its performance in each subsequent simulations.
Conclusion: My Takeaways
The engineering of a Formula 1 car is a complex and aerodynamic process that requires a deep understanding of physics, materials, and engineering principles. But as a fan of the sport and a CS engineer, I wanted to understand what it takes to dive deeper into the strategy and decision-making process of a Grand Prix. Optimizing Formula 1 Grand Prix strategies using Deep Reinforcement Learning is a fascinating and deeply complex challenge. By modeling the race environment as a Markov Decision Process and training a Deep Q-Network agent with a carefully constructed reward system, this project has shown that it's possible to create an AI system that can continuously adapt and refine race strategies based on real-time data.
To get the best out of the agent, I believe that it is important to enhance the reward system furtherby considering more factors such as detailed telemetry data. This includes precise tire wear indicators, track temperature changes, and complete car telemetry (like fuel loadand ERS deployment). Adding real-time weather data would also help the agent make better decisions about when to switch to rain tires. Including information about each driver's past performance and their car's unique characteristics could make the strategies even more personalized and effective.
Beyond improving the data inputs, we could also explore more advanced AI algorithms to make the agent smarter. Different reinforcement learning methods or combining multiple approaches might help the agent learn faster and create even better race strategies. As F1 keeps evolving with new rules and technology, the AI system can grow and adapt too, making it a powerful tool for future race strategy optimization.